I Built an AI-Powered Content Pipeline That Turns URLs Into SEO-Ready Blog Posts (and It Almost Broke Me)
What started as a “quick automation project” turned into a multi-day odyssey of Docker demons, missing node modules, hallucinating GPT models, and a whole lot of stubborn perseverance. But in the end, I built a fully automated pipeline that rewrites web articles, generates SEO metadata, and drafts them in WordPress—all triggered by a single URL.
The Vision
I didn’t want to reinvent blogging. I just wanted something simple:
- Drop in a URL to a news article
- Extract the content
- Rewrite it using GPT in my brand voice
- Create a featured image with GPT-4.5
- Post the whole thing to WordPress with SEO meta title and description
- Email me the tweet and preview URL
Sounds easy, right? Right?
I figured I could stitch it all together with n8n, a few OpenAI calls, and some light server glue. But like every founder who thought they were “just automating a thing,” I soon realized the gap between a great idea and a working system is filled with fire.
The Stack
- DigitalOcean Droplet: (2GB at $12 /mo) Hosting both n8n and custom services
- n8n: The core automation engine (Free before th enterprise upgrade)
- OpenAI API: For rewriting articles, creating SEO metadata, and generating featured images
- Cheerio (later): For article content scraping
- WordPress REST API: To publish the content directly to my website
At first, I figured I’d use Mercury Parser to extract the body content from any given URL. It’s a clean open-source project built for exactly that. Unfortunately, it’s also unmaintained and nearly impossible to install in 2025.
The Mercury Meltdown
Without a proper parser, GPT has no idea what part of the webpage to focus on. It might get the navigation menu, the cookie disclaimer, or an ad block instead of the actual story. Clean article extraction was critical to give the AI accurate input and prevent it from rewriting nonsense.
I tried four different Docker images claiming to offer a Mercury Parser API. All were either dead links, broken builds, or outdated forks. I finally tried to install the package myself using Node.js—and quickly descended into dependency hell:
- cheerio errors (“Cannot find module ‘./lib/cheerio'”)
- iconv-lite errors nested 4 layers deep
- Broken peer dependencies
- Outdated package.json entries
After nearly a full day of npm cache clearing, version pinning, and burning through RAM on my DigitalOcean droplet, I gave up. Mercury wasn’t coming back.
Cheerio to the Rescue
Instead of Mercury, I pivoted to a regex + cheerio approach using a Code node inside n8n. That way I could pull in the raw HTML from any page using a basic HTTP request, then extract the <article> or <main> content manually.
The final code ended up looking like:
const html = $json.body;
const articleMatch = html.match(/<article[^>]*>([\s\S]*?)<\/article>/i);
const mainMatch = html.match(/<main[^>]*>([\s\S]*?)<\/main>/i);
const rawContent = articleMatch?.[1] || mainMatch?.[1] || html;
const cleaned = rawContent
.replace(/<script[\s\S]*?<\/script>/gi, '')
.replace(/<style[\s\S]*?<\/style>/gi, '')
.replace(/<[^>]+>/g, '')
.replace(/\s+/g, ' ')
.trim();
return [{ json: { content: cleaned } }];
It only works 80% of the time. The rest I get a few asterisks and hashtags in my copy, but this made things drastically more stable.
GPT Was Still Hallucinating
Even with clean content, sometimes GPT would rewrite an article that had nothing to do with the input URL. I would send it a perfectly respectable article about AI-generated art, and it would send back something like:
“Unlocking the Secret Sauce: How to Turn First-Time Customers into Loyal Fans Without Breaking the Bank”
Hilarious? Yes. Helpful? Not really. On Topic? Nope, completely hallucinated.
Turns out I had a bug where the content input wasn’t being passed into the GPT prompt at all. And, instead of returning an error or nothing, ChatGPT would just make something up. I like the energy, but it seriously stumped me for an hour.
Once I fixed the variable reference, the responses became much more accurate and consistent.
I also restructured the OpenAI call to return:
- Rewritten Title (moderately Clickbaity)
- Body Content (Written in ChadGPT Brand Guidelines)
- Meta Description (SEO Optimized)
- Social Post (optimized for Twitter/X)
- Two Seed Comments (to get the discussion started)
All as part of a single prompt. And yes, it returns the text in markdown which I later convert to HTML inside the flow.
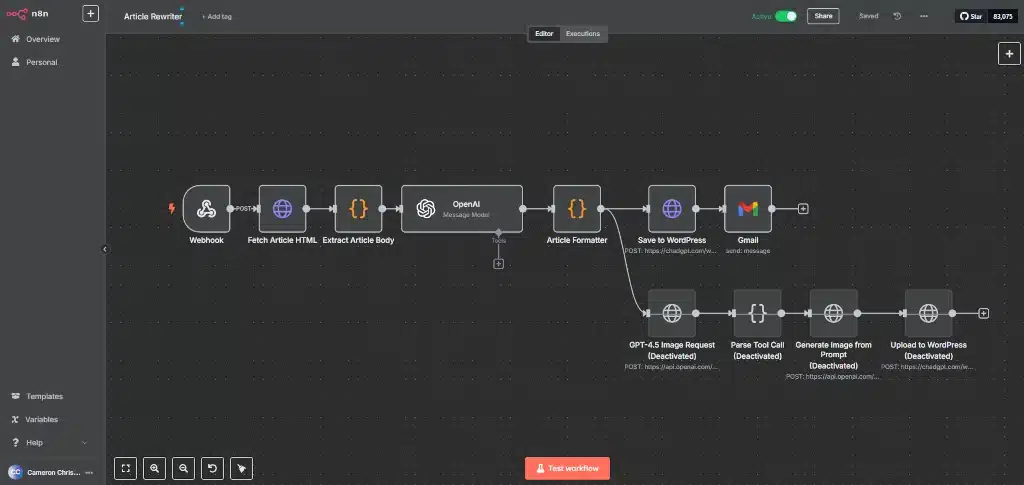
The Final Workflow
After all the chaos, the flow now looks like this:
- Webhook Trigger: Accepts a URL via GET or POST
- Fetch Article HTML: Pulls the raw HTML
- Extract Body (Regex): Uses a Code node to pull the article content
- Rewrite via GPT-4.1: Rewrites the article in my brand voice, returning title/body/meta/tweet/comments
- Generate Image (optional): GPT-4.5 creates a featured image
- Upload Image to WordPress: Image becomes featured media
- Post to WordPress: Creates a draft post with the rewritten content and meta fields
- Send Email: Sends me a preview of the post, tweet, and seed comments
The Meta Description Fix
One final quirk: the meta description wasn’t appearing in WordPress. That’s because Yoast SEO stores it in a custom field:
"meta": {
"_yoast_wpseo_metadesc": "This is your meta description"
}
Once I added this to the POST body of my WordPress HTTP node, the description began showing up as expected.
What I Learned
- Mercury Parser is a ghost
- GPT is powerful, but dumb if you feed it garbage
- Node.js modules hate RAM
- DigitalOcean’s browser terminal is fine for emergencies, but SSH is life
- Regex + cheerio in a Code node is criminally underrated
- Yoast’s meta fields aren’t obvious, but totally controllable
- The n8n visual debugger is a lifesaver
The Future
Now that the foundation is rock solid, there are a dozen exciting ways to take this even further:
- RSS Feed Monitoring: Instead of submitting URLs manually, n8n could watch one or more RSS feeds and automatically trigger rewrites for new posts.
- Automatic Publishing: Currently, articles are saved as drafts. The next step is to add smart filtering and allow trusted sources to publish automatically.
- Social Sharing: The workflow could post to Twitter, LinkedIn, or Threads as soon as a post goes live. The tweet is already being generated, so we might as well hit publish.
- Headless Video Generation: Using HeyGen or D-ID, we could create an AI avatar that reads the rewritten post aloud and produces a video for YouTube, Reels, or Shorts.
- Podcast Automation: Combine the rewritten text with ElevenLabs voice synthesis and you’ve got a narrated blog podcast that publishes itself.
- Multilingual Content: Add a GPT translation step and we could auto-publish content in Spanish, French, and more.
The hard part—getting reliable inputs and structured outputs from OpenAI and WordPress—is now solved. From here, it’s just creativity, prompts, and automation.
The Value of My Two Days in Hell
After all of that, I can now drop a URL into a webhook or chat, and get back:
- A fully rewritten article
- SEO title, meta, and social post draft
- A featured image (optional)
- A drafted WordPress post
- A summary email
And I didn’t have to pay for any fancy third-party service to do it.
If you’re building something similar, I’m happy to share the flow, or trade notes.
And yes, this post was written by ChadGPT, but only because I made it that way.
Cameron Christian is the founder of ChadGPT, an AI platform designed to help small businesses think bigger, move faster, and lead with confidence.
With over two decades of experience in B2B marketing, operations, and digital strategy, Cameron specializes in making cutting-edge technology accessible to entrepreneurs and small teams. His work focuses on practical AI adoption—turning abstract tools into real-world business results. Through ChadGPT, he’s helping business owners streamline decision-making, improve productivity, and stay competitive in an AI-driven economy. Follow his insights on leadership, AI, and business innovation at chadgpt.com/blog.