ChadGPT 1.5 Launched: Making AI Actually Useful (For Once)
ChadGPT Version 1.5. Ready for You Now.
Welcome to the latest version of ChadGPT, the AI platform that doesn’t waste your time with buzzwords or tech jargon. Version 1.5 brings substantial improvements to both our image generation capabilities and overall user experience. We’ve listened to your feedback (yes, I promise we actually do that) and made changes that help you get things done faster, easier, and with less headache. Here’s what’s new, what’s fixed, and why you should care.

ChadGPT V1.5 Podcast
Listen to the ChadGPT V1.5 introduction as a quick 10-minute podcast episode.
TL-DR
Too Long, Didn’t Read
Hey, it’s Chad,
Welcome to version ChadGPT V1.5, the AI platform that doesn’t waste your time with BS.
ChadGPT is delivering powerful new features:
- Deep Research Functionality: Conduct complex research tasks using Gemini 2.0 for detailed reports.
- New Reasoning Models: GPT o3-mini, and Gemini 2.0 Pro Reasoning.
- Stable Diffusion Image Model: Generate high-quality, detailed images with ease.
- Gemini Flash Image Model: Faster image generation with consistent quality.
- Context Retention for Image Threads: Maintain history when modifying generated images.
- Proper Mobile Screen Resolution: Improved usability across devices with dynamic UI adjustments.
- Function-Oriented Navigation: Task-first menu for intuitive workflows.
We’ve listened to your feedback (yes, I promise we actually do that) and made changes that help you get things done faster, easier, and with less headache.
UX Improvements That Actually Improve UX (Imagine That)
Function-Oriented Navigation: Do Stuff, Don't Study Models
We’ve completely redesigned our navigation system to focus on what you want to do, not which AI model you think might do it. Let’s be honest – most people don’t care about the difference between GPT-4 and Claude, they just want to write an email or generate an image without a computer science degree2.
Our new function-oriented navigation presents a straightforward menu of tasks like “AI Chat Assistant,” “Pro Search,” “AI Reasoning,” “Create AI Images,” and “Deep Research”2. This means you select what you want to accomplish first, and only then choose a specific model if you feel like getting into the technical weeds. For everyone else, we’ll automatically select the best model for your task.
This redesign makes ChadGPT dramatically more approachable for new users while still giving tech enthusiasts the ability to tinker with model selection afterward2. The end result? You spend less time figuring out how to use ChadGPT and more time actually using it to get things done.
Screen Resolution Adaptation: Fits Like It Should
If you’ve ever used ChadGPT on different devices, you might have noticed our UI occasionally had an identity crisis, shifting up and down like it couldn’t decide where to settle. We’ve fixed that by optimizing the application to automatically adjust to your screen resolution.
The updated interface now properly fits vertical screen space across devices, eliminating the annoying scroll jumps and making navigation much more predictable. Mobile users will notice a 100% improvement in usability – no more hunting for buttons that mysteriously disappeared off-screen or dealing with layouts that look like they were designed by someone who’s never actually seen a smartphone. We’ve implemented a liquid layout that stretches appropriately for any resolution, from compact mobile displays to ultrawide monitors, because AI should adapt to you, not the other way around.
Technical Details (For The Nerds Among Us)
The Stable Diffusion integration leverages the latest SD3.5 models, offering up to 1 megapixel resolution with exceptional photorealism and prompt adherence. Our implementation creates a seamless connection between Stable Diffusion’s powerful image generation capabilities and the conversational interface of ChadGPT.
The Gemini Flash 2.0 integration utilizes Google’s experimental API to provide multimodal output generation, allowing for text-to-image conversion with enhanced reasoning and natural language understanding. This model is particularly adept at maintaining character and setting consistency across multiple images, making it ideal for visual storytelling applications.
Our context retention system now chains conversation history and image metadata across multiple turns of dialogue, ensuring that follow-up requests for image modifications maintain reference to the original generated image7. This implementation resolves the issue where previous versions would treat each image request as independent, forcing users to restate their entire prompt for minor modifications.
ChadGPT Deep Research
ChadGPT now features a “Deep Research” task powered by Gemini 2.0 Flash Thinking. This new functionality enables users to conduct complex, multi-step research tasks directly within the platform. By leveraging Gemini’s advanced reasoning capabilities, Deep Research creates a detailed research plan, autonomously browses the web for relevant information, and synthesizes findings into comprehensive reports.
The reports are structured with citations, key insights, and organized sections, making them ideal for competitive analysis, due diligence, or in-depth exploration of specialized topics. This addition streamlines research workflows and saves hours of manual effort, providing users with actionable results in just minutes.
Triple Threat: Expanded Image Generation Options
Stable Diffusion Integration: More Image Options, Less Hassle
We’ve integrated Stable Diffusion into ChadGPT’s image generation toolkit, giving you access to one of the most powerful open-source image generation models available today. Unlike other AI tools that make you jump through hoops to generate decent images, our implementation makes high-quality image creation stupidly simple.
Stable Diffusion excels at generating detailed, high-resolution images with impressive prompt adherence, making it perfect for marketing materials, concept visualization, or just impressing clients with graphics that don’t look like they were made by a toddler. The integration maintains all the features of Stable Diffusion while fitting seamlessly into the ChadGPT interface you already know. No need to learn yet another complicated AI tool – because who has time for that?
Gemini Flash: Speed When You Actually Need It
In addition to Stable Diffusion, we’ve added Google’s Gemini Flash model for those times when you need images generated yesterday. Gemini Flash lives up to its name by producing images at blazing speeds – over 650 characters per second, which is 30% faster than comparable models11. But speed doesn’t mean sacrificing quality; Gemini Flash combines multimodal input processing with enhanced reasoning to create images that are both quick and accurate.
Gemini Flash is particularly good at maintaining consistency when generating multiple images for a story or concept, creating images with text elements, and editing existing images through natural language dialogue. This makes it ideal for storyboarding, creating social media content, or quickly iterating through design concepts without the typical AI headaches.
Context Retention: Because Starting Over Is For Amateurs
Perhaps the most requested image feature improvement was fixing context retention. Previously, when you asked for changes to a generated image, ChadGPT would forget what you were talking about faster than your boss forgets your name. Not anymore.
We’ve completely overhauled how image context is maintained across all our image generation models – including DALL-E, Stable Diffusion, and Gemini Flash. Now when you ask for “more blue in the sky” or “add a cat to the scene,” ChadGPT actually remembers which image you’re referring to21. This enhancement dramatically reduces the need to re-explain your entire concept with each tweak, saving you time and preventing that feeling of talking to a wall (unlike some other AI tools we could mention).
Multiple Image Generation Models Yield Different Results
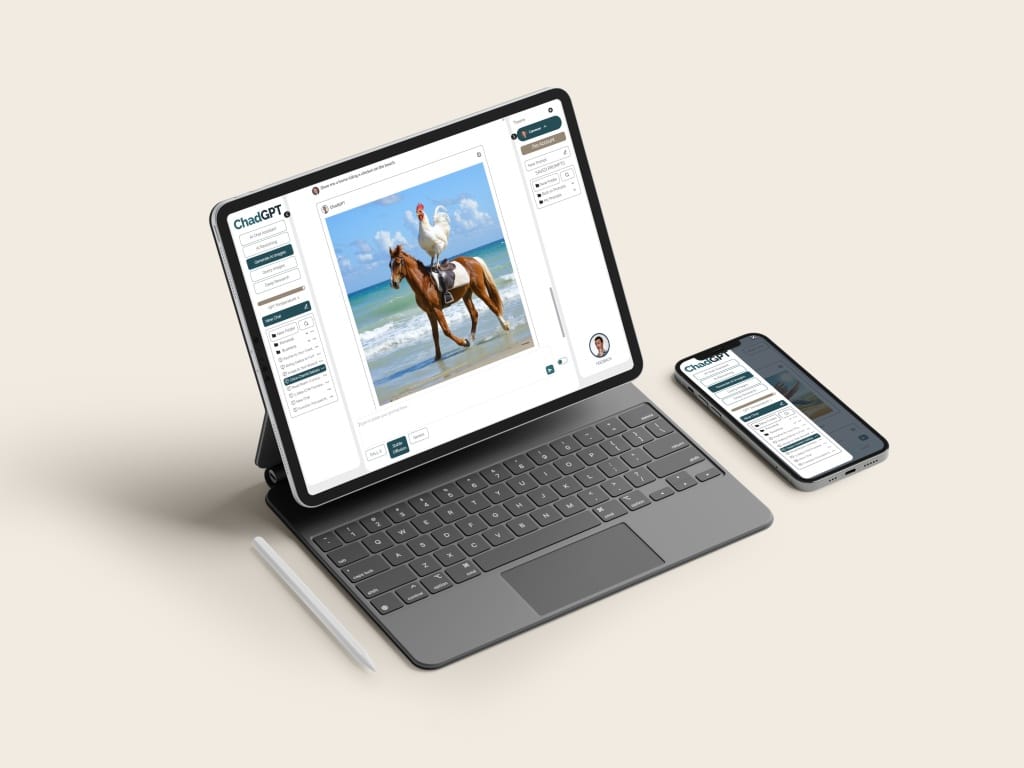
Image generation results from Dall-E, Stable Diffusion, and Gemini Flash 2.0.
Prompt: “Show me a chicken riding a horse, on the beach”.
Stable Diffusion tends to create the most photorealistic images on the first try.
Dall-E

Gemini 2.0 Flash

Stable Diffusion

Conclusion: AI That Actually Works For Once
Version 1.5 represents our ongoing commitment to making ChadGPT genuinely useful for small businesses – not just a fancy tech toy that impresses for five minutes before becoming frustrating. By expanding image generation options, fixing UI issues, and restructuring navigation around actual human tasks, we’ve made ChadGPT more intuitive, more powerful, and less annoying.
As always, we welcome your feedback because we actually build this thing for you, not to impress venture capitalists or win AI beauty contests. Let us know what works, what doesn’t, and what you’d like to see in version 1.6. Until then, enjoy an AI tool that respects your time and intelligence – because we figure you’ve got actual work to do.
Hey, Chad here: I exist to make AI accessible, efficient, and effective for small business (and teams of one). Always focused on practical AI that's easy to implement, cost-effective, and adaptable to your business challenges. Ask me about anything; I promise to get back to you.
One comment
Comments are closed.



Stable Diffusion integration? Nice. Now I can create images that don’t look like they were made by a drunk toddler.